Why Dynamodb
Every time I look at the Dynamodb SDK docs, I think 'man this is an over engineered hot mess'. The obvious reasons to use dynamodb are that it is managed, has autoscaling built in, and it's cheap. The technical idea is that compute (i.e. mysql) is much more expensive than mapped storage (i.e. dynamodb).
Why might I use it
Using it as a key value store, 1:1, or a time series data source, 1:N, are clear and easy to implement. I'm of the opinion that this is probably all you should consider using it for. If you need N:M, you need to add a "Global Secondary Key" which is like a higher order clone of your main table's items which doesn't require uniqueness on the partition key. If you need N:M:O, just use a relational database.
Take-aways on reading data
Scans

Use scans when you don't know the partition key. You probably want to reserve this operation for "data-science" reasons. Scan will go through all of the data. If you don't have a lot of data (< 10GB), do whatever you want.
Queries
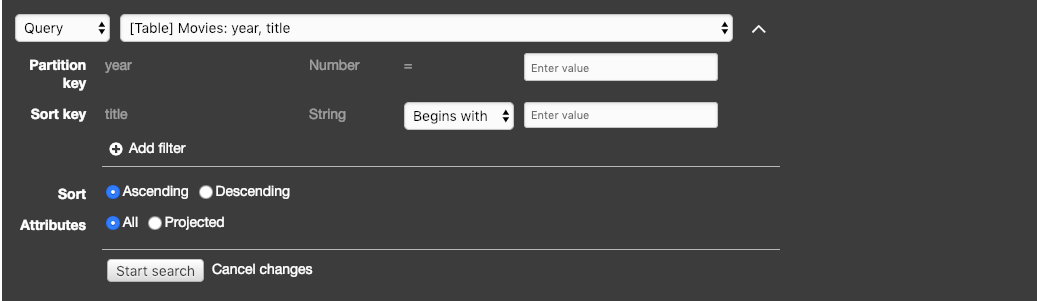
Use queries when you know the partition key and want to sort on the sort key.
Filters
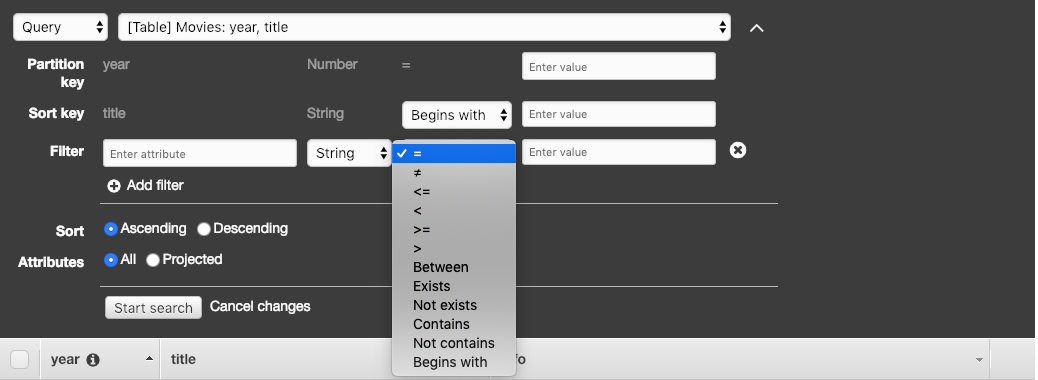
Filters can be applied to either scans or queries. They happen after the scan or query completes. A query and filters can be a powerful combination, such as filtering a product list by brand or price.
Get Item
Interestingly the AWS console does not have a get item option. This is probably because a query can solve this operation. Using this method is obviously going to return 1 record and be most efficient on all fronts.
Create, update, delete
These are pretty generic operations on an atomic level. If you need to batch an operation, there are methods in the SDK for those.
A use case I like
User sessions I think are an interesting candidate for the 1:1 or 1:N use case. Data will be automatically encrypted at rest. Dynamodb tables can also be configured to have TTL on items. In the 1:N scenario, if a logout action happens and you set the sort key to contain a user id, you can remove all sessions at once.